optimistic-model-learn.github.io
Optimistic Exploration in Reinforcement Learning Using Symbolic Model Estimates
TL;DR: use of symbolic action models improves exploration, which, in turn, allows us to automatically improve these models. The result: not just tasks solved faster, but reusable lifted action models, generalizing not just to new goals, but new objects as well.
Code Repository
It is no great exaggeration to claim that effective exploration remains one of the biggest bottlenecks in scaling up reinforcement learning (RL) agents in sparse reward domains.

A screenshot of a sample Minigrid environment
Consider the Minigrid domain – even in this relatively simple domain, exploration remains a challenging problem, even for state of the art methods. We propose a simple solution: learn an optimistic symbolic model approximates for the task and use these models to drive the exploration process. In particular, these symbolic models are used to efficiently generate potential plans (using symbolic planners). The plans are tested in the environment and the results are used to update the current estimate of the symbolic models. The process is repeated until a valid plan is found. The exploration is being driven by the plans for the approximate model and each update to the model allows us to make more informed choices about how to get to the goal.
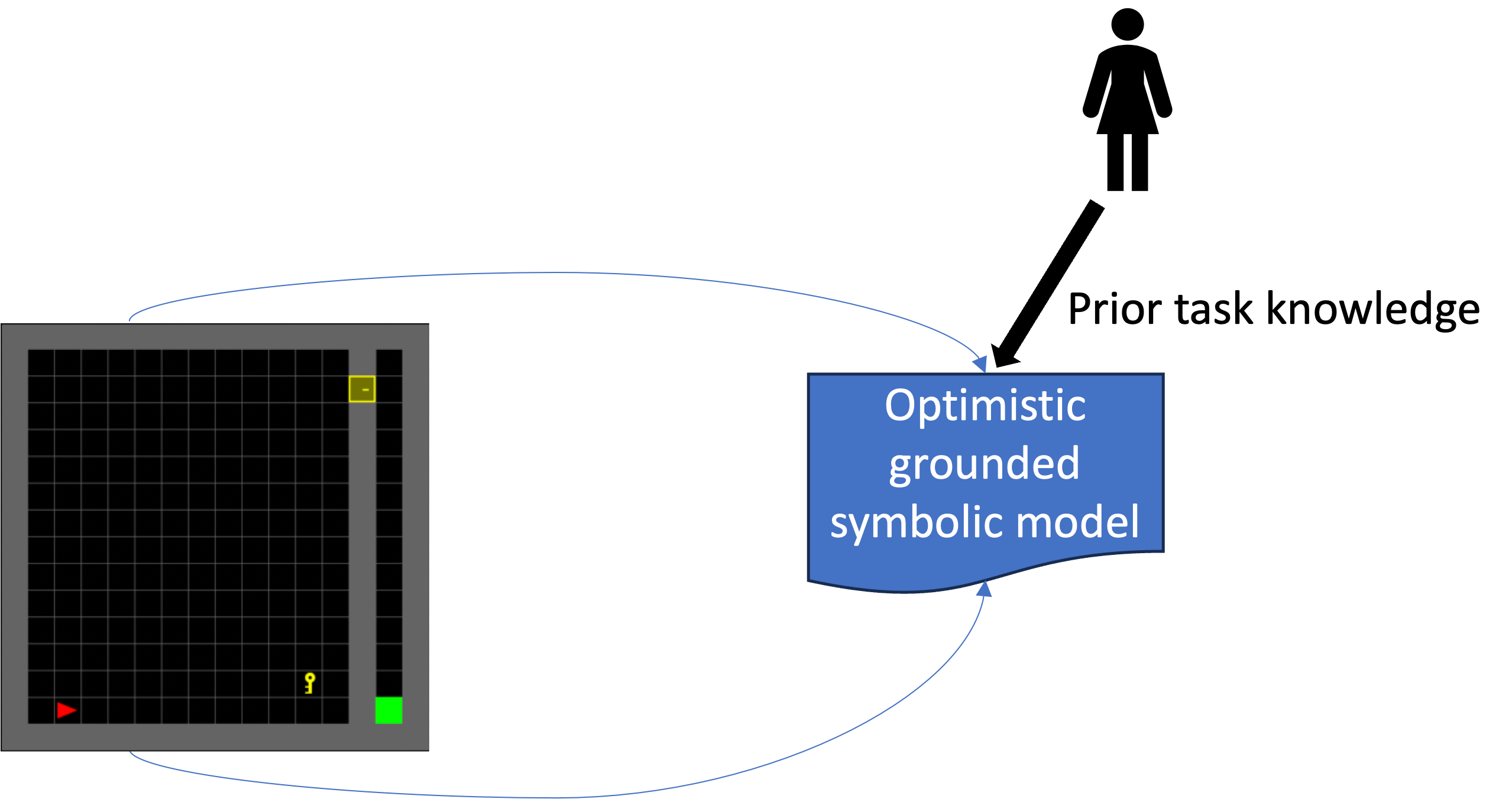
Proposed model learning method
There are multiple advantages to using a symbolic model, such as a planning model, expressed in a formal language (e.g., PDDL). The use of these inherently interpretable models makes it easy to incorporate prior knowledge humans might have into the model. But more importantly, it provides us with an opportunity to easily introduce two novel considerations into the exploration process: the ability to leverage a novel form of optimism in the exploration process, optimism with respect to transition function, and allows us to leverage a novel form of generalization, generalization of learned action dynamics across different objects.
Learning Symbolic Planning Models
Most existing works in learning symbolic models focus on learning planning models from plan traces. In particular, the focus has been to develop methods to learn what would be considered safe models. Under this learning regime, the focus is to guarantee that the plans supported are a subset of the plans supported in the learned model, i.e., a pessimistic model.
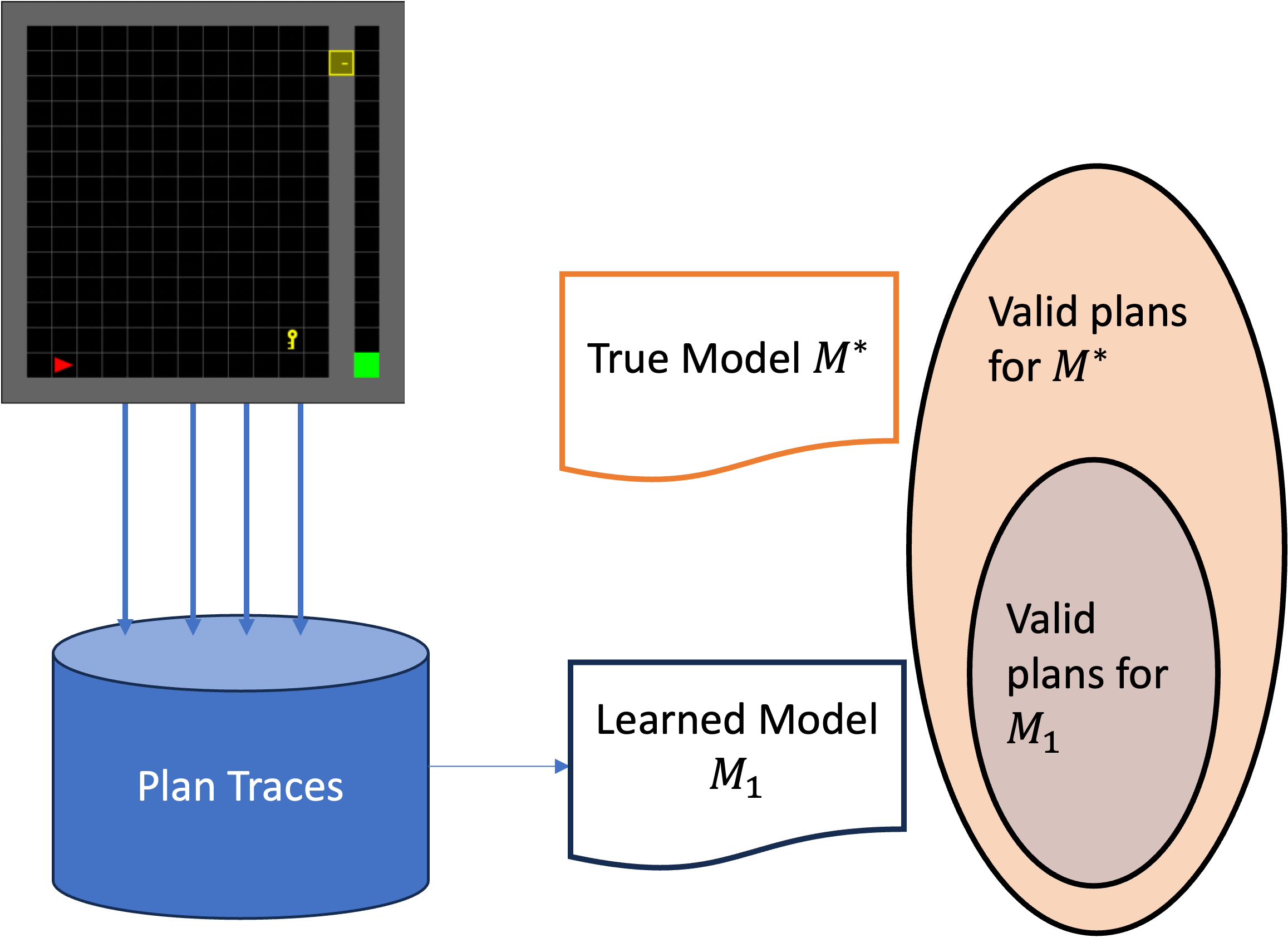
Pessimistic model
This works well for settings where the execution of an invalid plan may be unacceptable. This may be ineffective in traditional settings where we can afford to try out different possible plans.
Our goal was different: to learn an optimistic model, one that allows for more plans than are possible in the true model. One could easily couple such a model with a generic symbolic planner, iterating over the plan space (e.g., a diverse or top-k planner) until a valid plan is found.
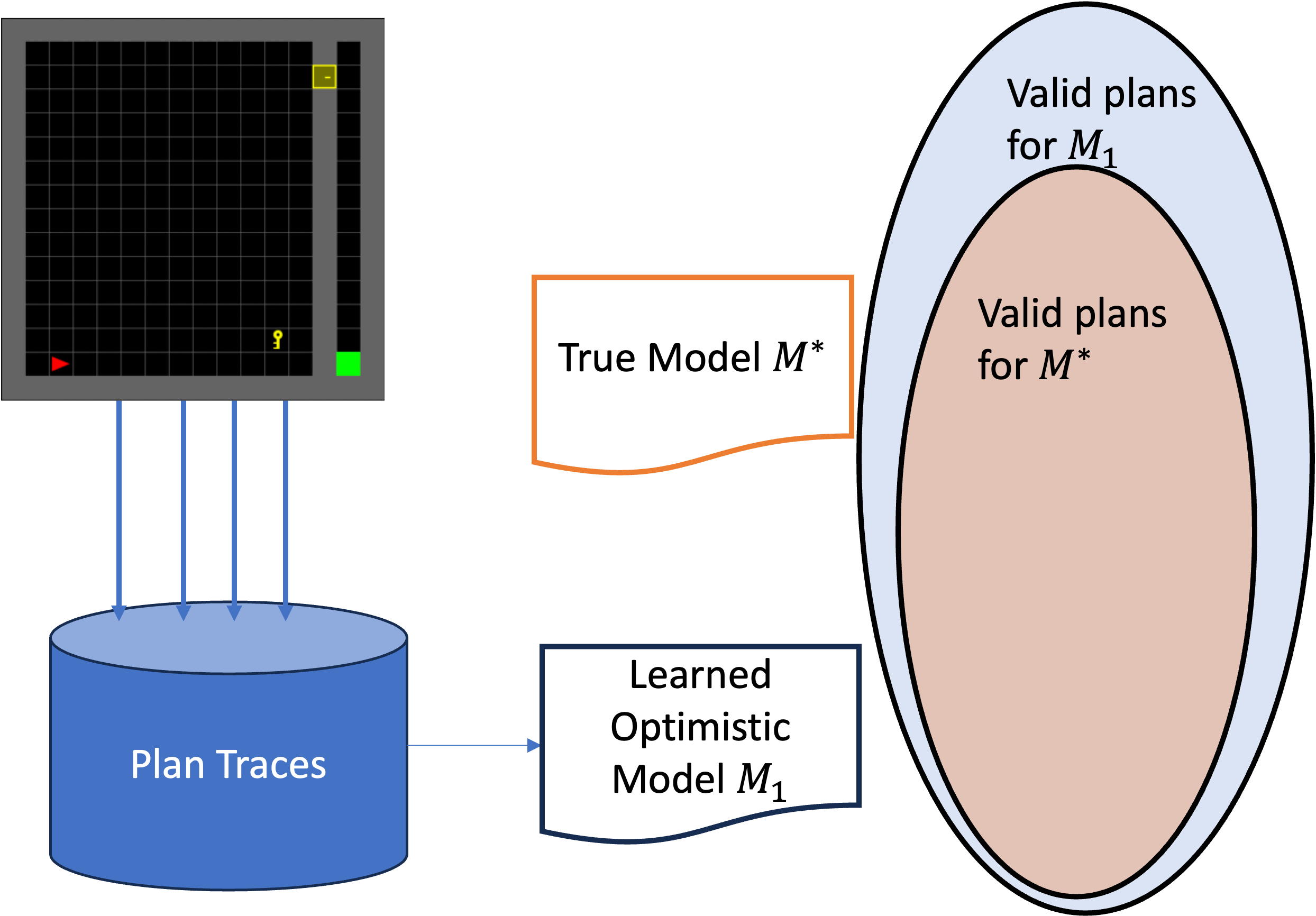
Optimistic model
Overall Learning System
With the new model learning method in place, we can discuss how this model fits into the overall learning system. Below, we provide a schematic overview of the overall learning system. As discussed before, we start with an optimistic estimate of the model. We then use a diverse planner to generate candidate plans for that model. These plans are then tested on the simulators. The experiences generated from the simulator are used to update and refine our optimistic model. Once a plan that corresponds to a successful trace is identified, this information is used to initialize the RL algorithm. For our experiments, we focused on Q-learning: the plans were used to initialize the Q values with more informative estimates.
An overview of the overall learning system
Lifted Representation as a Form of Generalization
We mentioned earlier the idea of using symbolic models as a way to support a novel form of generalization. The underlying concept is fairly simple: one could define the structure of an action model (its preconditions and effects) independently of the specific objects over which it operates. In the Minigrid, if the agent can learn how to pick up the yellow key in the lower right corner of the left room, it should also be able to pick up a blue or green key in any location.
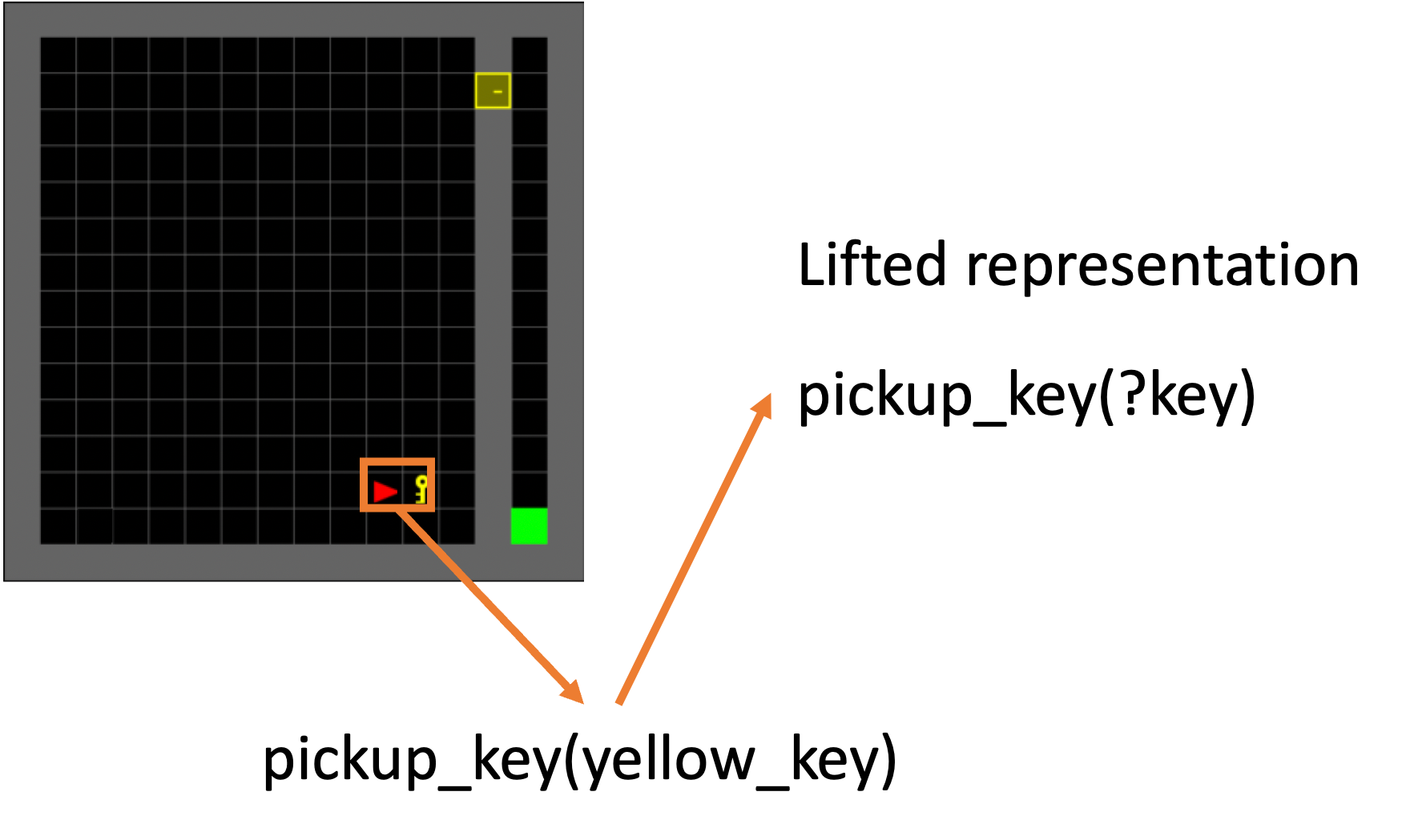
An example of how our system is able to learn lifted representations.
Our method allows us to learn such lifted action models and therefore transfer the information learned about a specific action instance across various ‘grounded copies’ of the same lifted actions. This form of generalization also provides us with an opportunity for a new form of curriculum learning: we can learn lifted model information in problem instances that have a smaller number of objects and then use the learned model to solve larger problems.